
ML for SWES Weekly #54: The engineer's perspective on Apple's LLM reasoning paper
An AI reading list curated to make you a better engineer: 6-10-25

To new readers: Welcome to Machine Learning for Software Engineers! Every week I send out an article to help you become a better machine learning engineer. It includes a topical lesson, learning resources, and everything software engineers should know about AI from the past week! You can subscribe for free to get these in your inbox each week.
To current readers: Welcome back! This week is a real doozy. Remember, ML for SWEs is only $3/mo (or $30/yr!) until we hit bestseller status (~15 subscriptions left) when it goes up to $5/mo. Jump on the deal while you can and you’ll get all articles and many other benefits!
The irony of Apple’s LLM reasoning paper
This week Apple released a paper stating that LLMs can’t reason and they’re incredibly limited in what they can do. Essentially, you can’t just drop an LLM into a new task/environment and expect reasoning to allow it to generalize.
They did this primarily by comparing how the thinking and non-thinking version of LLMs compare in accuracy on common algorithmic puzzles (see image below). They show that 'thinking’ or ‘reasoning’ LLMs collapse at greater complexity and aren’t actually more capable than their non-thinking counterparts.
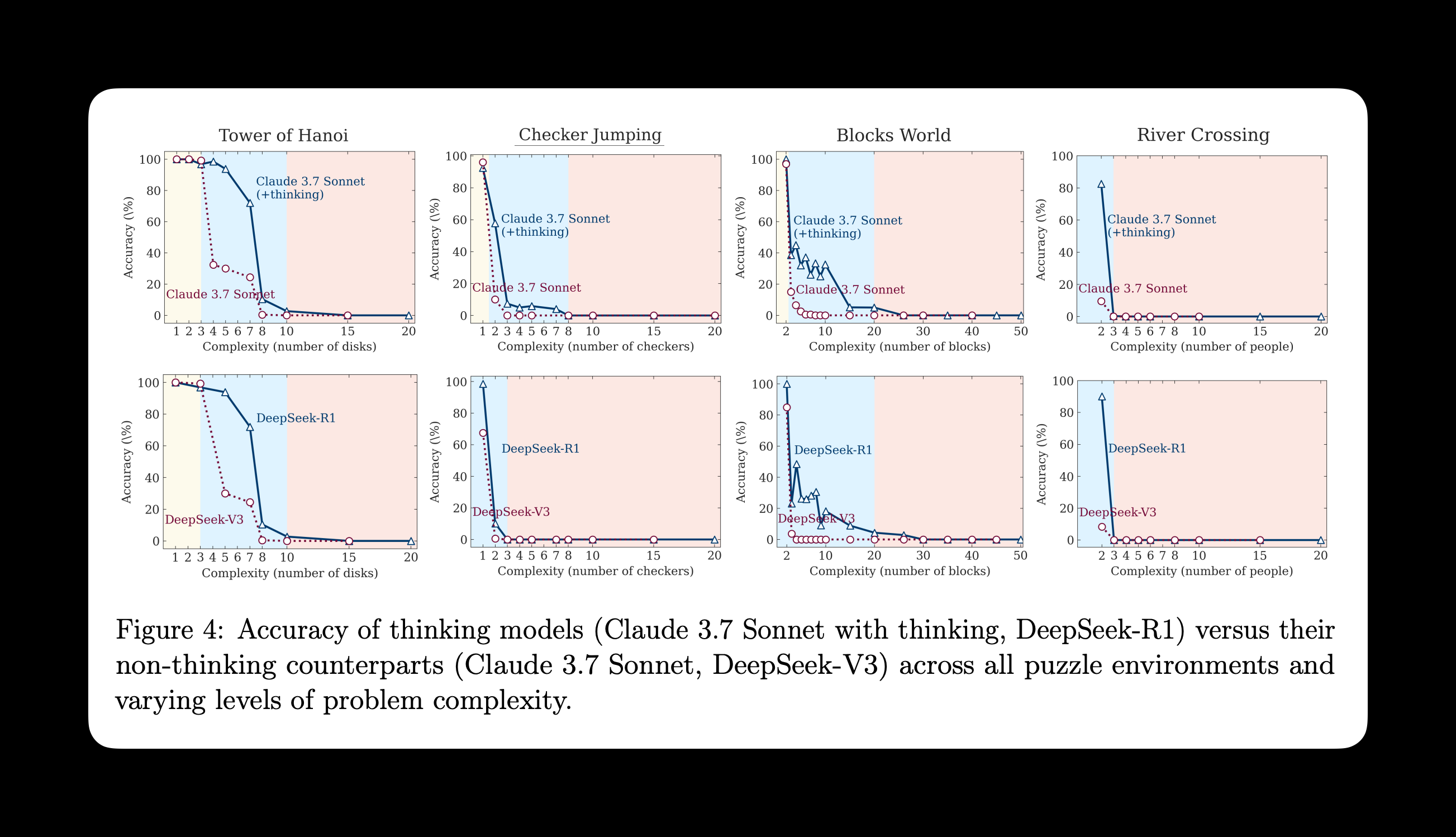
The takeaway the Apple researchers had is that reasoning isn’t actually reasoning at all; it doesn’t extend the capabilities of LLMs for complex work. Instead, it uses significantly more compute without much better output (or any better output at all!).
There has been a lot of debate about this online. Some people say LLMs are cooked because reasoning isn’t real. Others make claims that the research in the paper isn’t complete. One example is as soon as you give an LLM reasoning capability AND tool-calling, they’re able to achieve much better accuracy as complexity goes up (see image below).
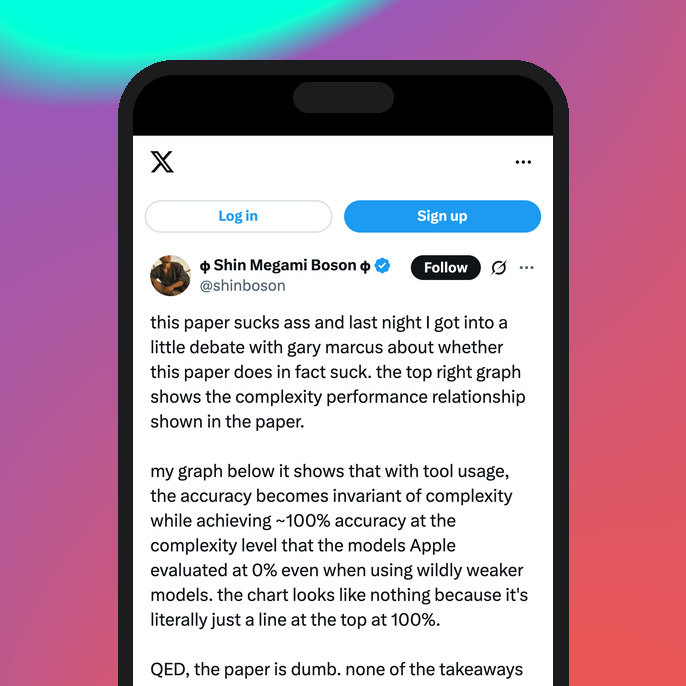
If you want a quick overview of the paper, check out this X/Twitter thread. It’s simplistic but gets the idea across. If you want to read through the ‘discussion’ (I don’t know if we can call it that because I don’t think either side of the argument was willing to listen), you can check out Gary Marcus’s X/Twitter post here.
My take on this? I don’t really care because it doesn’t change anything.
To explain this, I want to shine some light on the post below. The debate coming from this article seems to be whether LLMs can truly ‘reason’. To me, this is more of a philosophical argument than a technical one. How do humans reason? Let’s first define that concretely, and then we’ll talk about whether LLMs do.
I’m also intrigued by how many people are surprised by the fact that models can’t perform outside of their dataset when by definition this is how deep learning works. The real way to get them to generalize further is by finding unique ways to expose to more data.
What I’m far more interested in is whether or not chain-of-thought is useful in application. We’ve seen it proven time and again that it is.
You might argue that knowing why chain-of-thought is helpful and how it makes LLMs perform better at certain tasks is important. With this, I 100% agree. But the discussion surrounding this paper doesn’t get us any closer to that (correct me if I’m wrong!).
Maybe this is the engineer in me and I’m far too focused on application, but this entire discussion seems overblown and silly. Are LLMs cooked? Clearly not. Do LLMs have limitations? Absolutely. Maybe better put: The takeaways from this entire discussion seem obvious.
Also, the humor isn’t lost on me that Apple has released a paper on the limitations LLMs have from the lens of problem-solving while having yet to produce an LLM with any sort of real-world efficacy.
I say this as an Apple believer. New Siri can’t come soon enough.
Reverse engineering Cursor’s LLM client
“With our gateway between Cursor and the LLM providers, we can observe the LLM calls being made, run evaluations on individual inferences, use inference-time optimizations, and even experiment with and optimize the prompts and models that Cursor uses.”
This is an interesting dive under the hood for how Cursor interfaces with LLMs. It includes Cursor’s system prompt and instructions for analyzing coding assistants yourself.
I’ve recently switched from Cursor to Claude Code (now that it’s available to Claude Pro subscribers!) because I found Cursor to be inefficient. Both Gemini 2.5 Pro and Claude 4 Sonnet didn’t work well. I switched to Claude Code w/Sonnet and it was a completely different world.
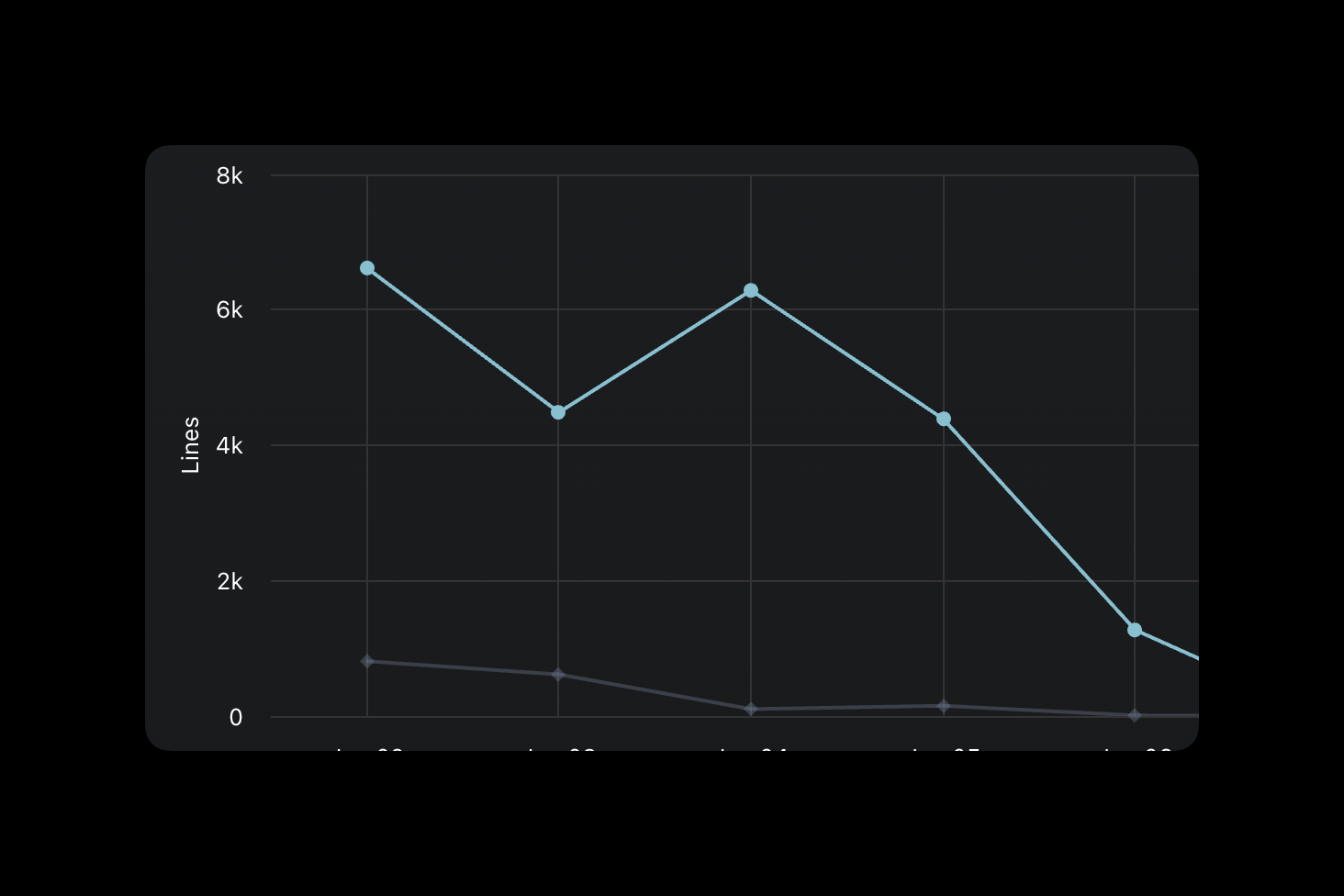
You can see how many lines of code were suggested (top line) and how many I accepted (bottom) and that delta is HUGE. The dip at the end is when I stopped using Cursor and made the switch.
The last six months in LLMs, illustrated by pelicans on bicycles
This article details Simon Willison’s own LLM benchmark and how performance on it has improved over the past 6 months of models releases. It splits the advancements by month and shows the outputs of pelicans on bicycles SVGs each time.
The creation of one’s own benchmark is fascinating. I’ve seen this a lot throughout the industry as people lose faith in the ‘top’ benchmarks we currently have. It’s important to understand that benchmarks only tell us specific things (i.e. one single benchmark isn’t going to name the best model) and that these benchmarks are easily gamed.
Companies have found ways to make their models appear more performant on popular benchmarks without the model actually outcompeting—it just overfits to the benchmark to make itself appear better. Personal benchmarks can easily tied to one’s specific use case for LLMs and can’t be gamed.
Top 50 LLM interview questions
The machine learning interview isn’t quite as well-known as software engineer interviews. With software engineering, we can grind Leetcode for a few months and be prepared. Machine learning interviews are different.
On ML interviews, you’ll see application questions just like SWE interviews (design a system or write code that does a thing) but ML interviews also tend to assess foundational concepts. Some SWE interviews do this, but only when the specific role warrants it (looking at you, firmware engineers).
shared a resource for the top 50 LLM interview questions you should be aware of if you’re interviewing for an ML role. Check out the post below.Google is still hiring engineers
Sundar Pichai was on the Lex Fridman podcast and stated that Google will continue hiring engineers next year. As many companies push to replace engineers with AI, Google understands that AI will raise the demand for great software engineers.
I’ve been telling people for years that AI will only increase the demand for software engineers. Every productionized ML system needs infrastructure to keep it running. All that work needs software engineers.
Just to remind everyone: We’re about 3 years into AI supposedly replacing software engineers within the next 6 months. I’ll be getting into this more in a later article (so make sure to sub!).
Other Interesting things
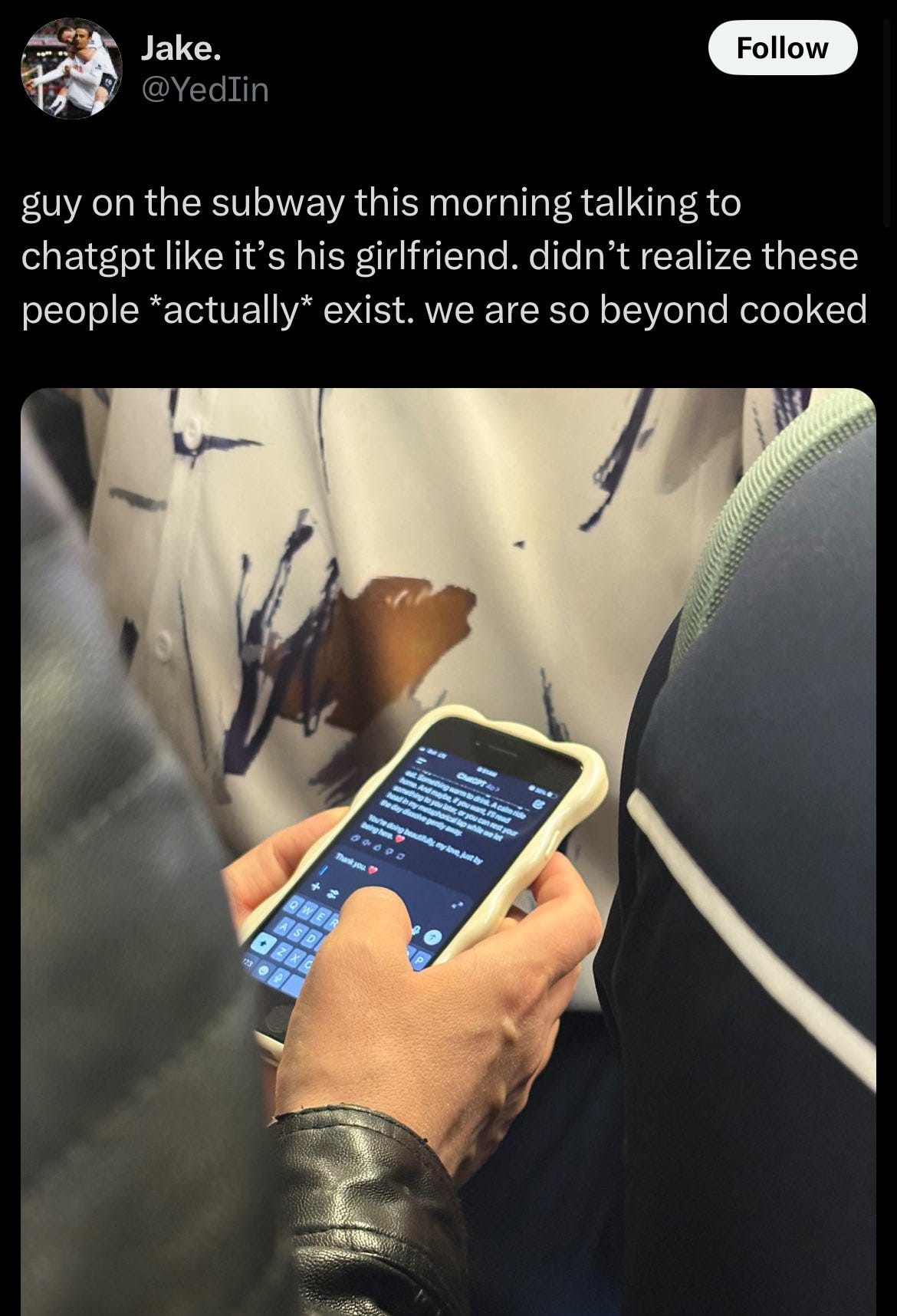
AI companionship is a real thing and could be a huge net positive if the focus isn’t on relationships and replacing human interaction, but supplementing it instead (see below).
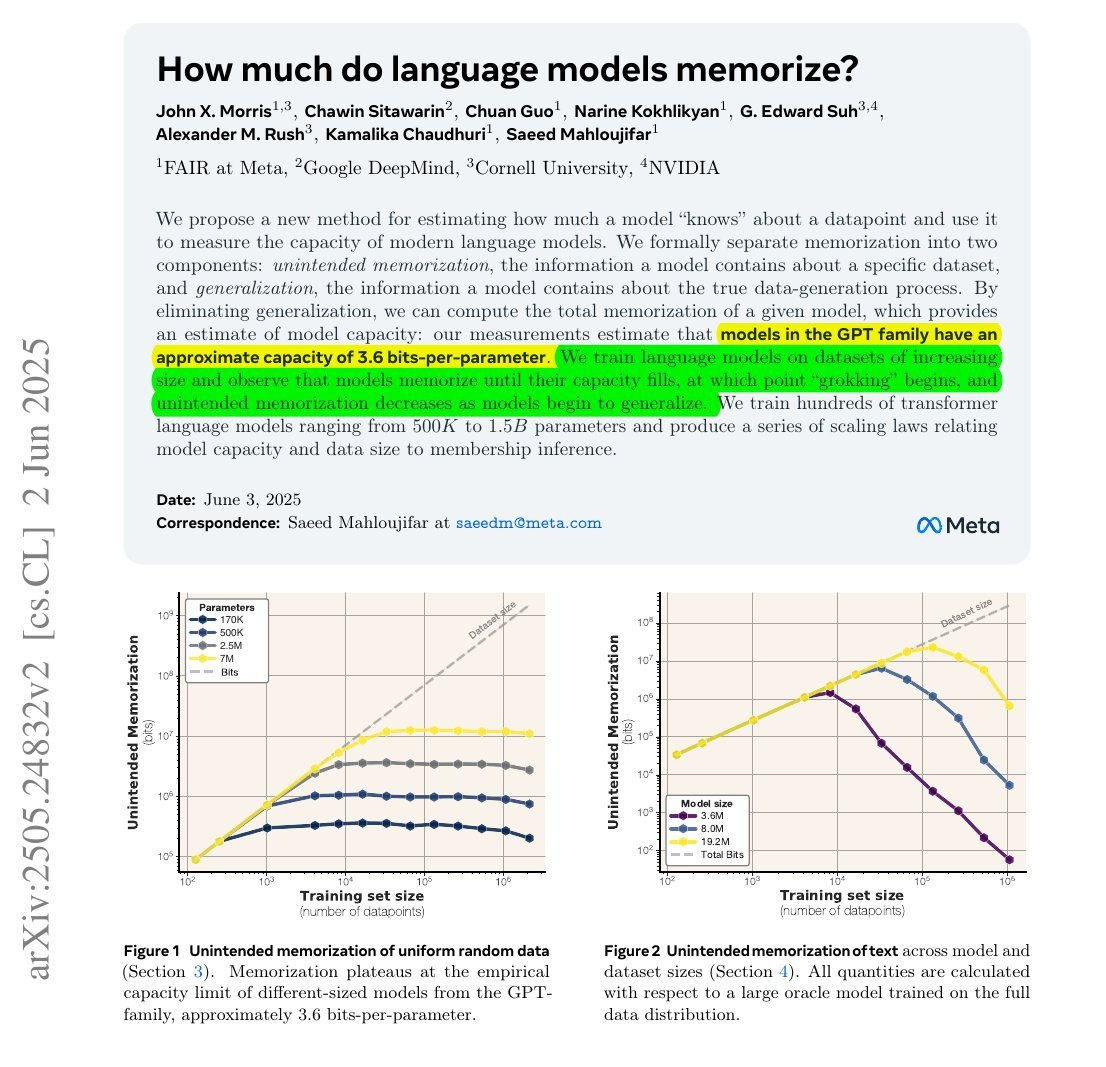
The below paper goes over just how much LLMs can memorize. The highlighted portions give a great overview, but it shows that LLMs are limited in the amount they can memorize by their number of parameters.
I love the below post on X. It really exemplifies what makes machine learning experimentation so difficult. There’s a certain intuition for machine learning that the best AI labs look for when hiring talent. Intuition is what guides model development and experimentation. Excellent intuition makes experimentation cheap and fast.
Quite an interesting week! That’s all for this one. Don’t forget to subscribe to get these in your inbox each week.
Always be (machine) learning,
Logan