

Welcome to Machine Learning for Software Engineers! Each week I curate insights and resources specifically for software engineers learning AI. This article includes:
Lessons
Learning resources
Current events
Jobs
That are helpful and important for software engineers learning AI. Subscribe to get these in your inbox each week.
If you find Machine Learning for Software Engineers helpful, consider becoming a paid subscriber for just $3/month forever for a limited time.
If you missed us last week, go back and get a refresher! There is an important lesson for all engineers here:

Transformers may only get us so far
We’ve got a video this week! If you want to watch/listen to the most important lesson this week, check the video above.
We constantly see people talking about how LLMs won't get us to AGI. It's interesting because most of these people are talking about scaling, that LLMs won't scale when we give them more resources and that's their argument about LLMs not getting us to AGI.
Now putting aside the fact that there isn't a proper definition for AGI, so nobody actually knows what it means to hit AGI, LLMs are fundamentally limited in many ways, but scaling doesn't seem to be one of them.
The data shows that we have been able to find ways to scale LLMs with more compute, more training time, more resources, more inference time, and more resources at inference time so they don't hit a wall with their scaling.
What's much more interesting about LLMs in the concept of AGI is whether or not the Transformer architecture is capable of general intelligence. We've seen very successful multimodal LLMs (even though they should really be large multimodal models, in my opinion) capable of taking in any medium as their input tokens and outputting any medium at their output.
But we've seen some cracks in the transformer architecture and what it's capable of:
We've seen transformer-based models have a tough time on the ARC-AGI contest (although this gets much better with tool calling and inference time scaling).
We've seen LLMs with long context windows struggle to utilize those long context windows appropriately.
We've seen examples of LLMs struggling to provide real-world value.
We've seen how expensive LLMs can get and companies struggle to be profitable when they're serving LLMs at scale.
We've seen LLMs become slow as they grow. That speed that they lose is fundamental their deteriorating usefulness in many applications.
Fundamentally we've seen there's limitations to what transformer-based models can do with the data that they're given. We've already seen machine learning and AI experts start looking in other directions to come up with proper generalized super intelligence.
François Chollet has moved on from Google and started a new company called Ndea where he's working on a different sort of world-view model. He's the creator of the ARC-AGI contest and has claimed that LLMs have limitations, so he's looking for a better solution to generalize superintelligence.
Yann LeCun has stated that LLMs aren't the answer, but they've opened up a new type of thinking. He's been outspoken about the limitations of LLMs and their usefulness and that they're a stepping stone to another type of model that can more efficiently process data and be more useful on a wider array of applications.
Google is experimenting with diffusion models for coding, to find a generative AI model that gives users greater control over the model's output and better speed in text generation.
We've seen researchers from Carnegie Mellon and Stanford create Cartesia, a company working on state space models (SSMs), which are tackling generative AI problems using a different model architecture.
Those last two are what I really want to focus on here. Diffusion models and SSMs are both different approaches at similar generative AI problems that transformer-based LLMs are trying to tackle both of which are trying to improve upon a fundamental deficiency with the transformer-based architecture.
SSMs are trying to do the same generative AI tasks in linear time instead of the quadratic time complexity in both compute and memory that the Transformer’s self-attention mechanism requires.
Diffusion models are trying to do the same generative AI task by working on an entire block of input at once instead of processing it token by token. This means diffusion models have the potential to output faster, to avoid the issues that transformer models have with long context, and avoid the issues transformer models have falling into repetitive loops or producing similar situations repeatedly.
I won't go any more in depth into transformer based architectures versus SSMs versus diffusion models because I think it really warrants its own article where we can have graphics and dive in a little bit deeper. If you want me to go over that, let me know in the comments.
The most important resource to read this week is Cartesia’s Chief Scientist and Co-Founders blog post analyzing the trade-offs of SSMs. I think SSMs are flying under the radar and not enough people talk about them. While I think SSMs particularly are important, I think it's more important to realize that maybe Transformers aren't the future. This has both hardware and software implications.

For now, enjoy the rest of these resources! We've got some great learning resources and awesome things that happened this week.
Particularly interesting are:
An article about how lines of code isn't a metric for productivity.
Mark Zuckerberg going HAM on hiring.
Programmable mini robots.
Kimmy K2: an open source, trillion parameter model that performs as well as Claude Code on coding tasks.
Google engineers seeking hires on X.
Learning resources to help you become a better engineer
Hierarchical Networks (H-Nets): H-Nets address the limitation of standard AI models processing all inputs uniformly, which often leads to failures with high-resolution raw data or unreliable pre-processing. They incorporate hierarchy natively through dynamic chunking and compression across an encoder, main network, and decoder, enabling more robust handling of complex inputs and direct learning from raw sources—essential for engineers pushing model boundaries.
Skilljar for Anthropic Courses: Skilljar serves as the learning management system for Anthropic's AI content, providing interactive experiences, progress tracking, and a central hub for resources. It's a practical tool for engineers seeking structured education on advanced topics like model development and safety.
Robust Multimodal Large Language Models Against Modality Conflict: This paper identifies "modality conflict"—clashing information across inputs like text and images—as a primary cause of hallucinations in multimodal LLMs. It introduces the MMMC dataset for evaluation and compares mitigation strategies: prompt engineering, supervised fine-tuning, and reinforcement learning, with RL proving most effective at reducing errors. Valuable for engineers building dependable multimodal applications in imperfect real-world conditions.
Weighted Multi-Prompt Learning with Description-free Large Language Model Distillation: DeMul bypasses the inconsistency of text descriptions by directly distilling LLM knowledge into weighted vector prompts for vision-language models. It achieves superior results on 11 recognition datasets through enhanced semantic capture, making it a go-to technique for engineers fine-tuning VLMs efficiently without extensive data.
Three Mighty Alerts for Hugging Face Infra: Hugging Face relies on targeted alerts for production stability, such as monitoring high NAT Gateway throughput to catch cloud traffic issues early. These practices are insightful for engineers scaling ML deployments and maintaining reliable systems.
Other interesting things
Reachy Mini Robot Kit: Reachy Mini is an accessible, 11-inch open-source robot programmable in Python. The $299 lite version features a wide-angle camera, speaker, and six-degree-of-freedom head; the $449 wireless adds a Raspberry Pi 5, WiFi, and battery. It's an engaging resource for engineers exploring AI in hardware, from vision to simple automation.
OpenAI’s Security Clampdown: Following allegations of model copying by competitors like DeepSeek, OpenAIimplemented measures including "information tenting" for restricted access, biometric controls, offline isolation of proprietary tech, a deny-by-default internet policy, and enhanced data center security. This reflects the growing emphasis on protecting intellectual property in the competitive AI space.
Meta Nabs Apple’s AI Models Head: Meta recruited Ruoming Pang, Apple's lead on foundation models powering Apple Intelligence, to bolster its superintelligence unit—part of a broader talent acquisition from places like DeepMind. It highlights the intense competition for expertise driving innovations in advanced and on-device AI.
Against AI ‘Brain Damage’: The study "Your Brain on ChatGPT" reveals that using AI for tasks like essay writing reduces engagement and retention, though it doesn't cause literal brain damage—mirroring historical concerns over technologies like calculators. It's a reminder for engineers to use AI mindfully to preserve cognitive skills in development work.
AI for Mental Health Initiatives: Initiatives include a field guide from Grand Challenges Canada and McKinsey for scaling evidence-based interventions, alongside Google, DeepMind, and Wellcome's multi-year funding for research into anxiety, depression, and psychosis. These efforts promise more effective, AI-enhanced mental health support.
Google Earth’s Journey: Starting as enterprise software at $800/year, Google Earth saved 4,000 lives during Hurricane Katrina and aided ecosystem discoveries; now, generative AI is evolving it into a predictive tool for planetary changes. It's an inspiring example of AI's transformative potential in practical applications.
AI Probing Human Minds: Research in Nature fine-tuned a large language model on 160 psychology experiments to predict behaviors, establishing a "foundation model of human cognition." This intersection of AI and psychology offers engineers new ways to understand and improve system designs inspired by human thought.
AI Training for Teachers: OpenAI partnered with the American Federation of Teachers for a five-year, $10 million National Academy for AI Instruction, aiming to train 400,000 K-12 educators with support from Microsoft and Anthropic. It's a forward-thinking move to integrate AI responsibly in education.
xAI’s Grok 4 Launch: Grok 4 from xAI supports image analysis and questions, with claims of PhD-level performance across subjects, available via a $300/month SuperGrok Heavy subscription. It represents exciting progress in making sophisticated AI more approachable.
Open vs. Closed Models: Executives from GM, Zoom, and IBM explored trade-offs in open, closed, or hybrid AI models, considering factors like cost, performance, trust, and safety. IBM's model-switching gateway suggests hybrids as a balanced option for enterprise engineers.
Microsoft AI Savings Post-Layoffs: Microsoft's AI tools generated $500 million in call center savings last year, announced shortly after 15,000 layoffs amid $26 billion quarterly profits. It illustrates the dual impact of AI on efficiency and employment.
Forget AGI, Chase GPAI: Rather than distant AGI, focus on General-Purpose AI (GPAI) as an achievable target, with a roadmap emphasizing versatility and integration for immediate, tangible benefits in engineering applications.
Kimi K2 Model: Kimi K2 is a mixture-of-experts model with 1 trillion parameters (32 billion active), trained on 15.5 trillion tokens using the Muon optimizer. It stands out in knowledge, reasoning, coding, and agentic capabilities like tool use, ideal for cutting-edge engineering tasks.
Quick Software Building Tips: Development involves inevitable trade-offs between time and quality—target an 8/10 level on schedule, addressing minor issues later. This approach aligns well with the fast-paced iterations common in AI engineering.
Meta Acquires Play AI: Meta’s acquisition of Play AI brings human-like voice generation and an intuitive platform, with the team enhancing Meta's AI characters, wearables, and audio features, advancing more lifelike interactions.
Multi-Agent Systems: Beyond single agents, multi-agent systems involve multiple entities coordinating or competing in shared environments to solve intricate problems, offering engineers a powerful way to scale AI for distributed challenges.
Negative 2K Lines Story: In 1982, the Lisa software team decided to track developer velocity by lines of code they added, requiring the developers to log their lines of code each week. To prove how silly that metric is, a developer decided to focus on removing code from their codebase to streamline it and put -2000 on the weekly report.

Supervising AI Insight: Effective oversight of AI tools or teams requires the ability to perform the task yourself, even if infrequently—like managers retaining coding skills. It ensures grounded, practical guidance in engineering contexts.
Jobs
Interestingly, Google engineers have been seeking developers are X/Twitter instead of through standard means. I think recruiting like this will only be more common and makes it even more important for you to be learning and building in public.
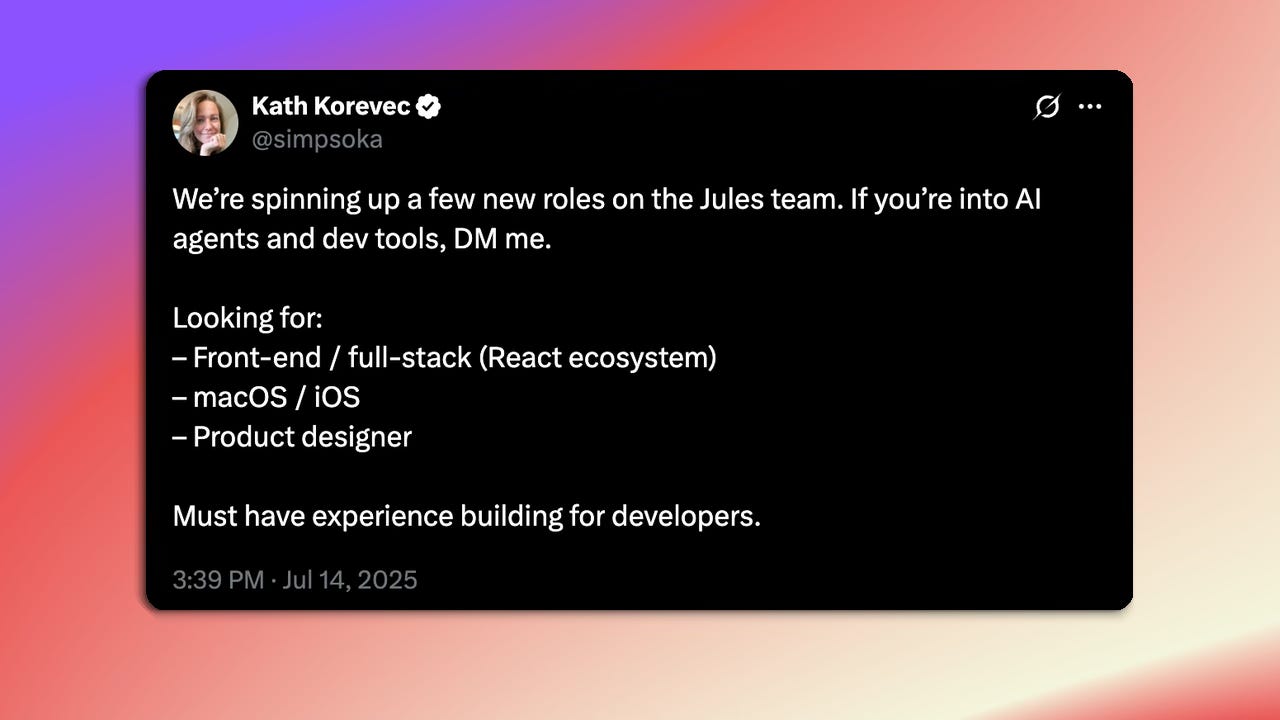
Roles on the Jules Team at Google Labs: Google Labs is hiring for the Jules team, focused on AI agents and developer tools. Positions include front-end/full-stack (React ecosystem), macOS/iOS, and product designer. Must have experience building for developers. They are looking for someone in the PST time zone.

AI Developer Frameworks and Tools at Google: Looking for experts in TypeScript or Python to work on next-generation AI developer frameworks and tools at Google. The role sits at the intersection of foundational research and engineering, applying research to real developer products with plenty of freedom and opportunities. If interested, DM @rakyll with resumes (Googlers can reach out internally).
That’s all for jobs this week. I’m trying to determine a more beneficial way of sharing jobs in these roundups that will be coming soon!
Thanks for reading!
Always be (machine) learning,
Logan
