
Spotify ML Case Study: AI Has Fundamentally Changed the Music Industry
A case study of Spotify's algorithm, including how it works and the impact it has

This is part one of a series. In this part, I detail how Spotify's recommendation system works and the real-world impact it has (both advertently and inadvertently). In the next part, I will go over how to build a simple recommendation system similar to Spotify's.
I'm certain you've heard the phrase: "Music is terrible these days." This was likely from someone who grew up in the 1980s or earlier remarking about the style of music the 'youngins' listen to and what's been playing on the radio recently. Most of us roll our eyes because every generation seems to think the next generation's music is garbage, but the truth is that music has changed drastically over the past decade.

Generative AI has caused more people to be conscious of how AI impacts everyday life. This is easy to notice when a person frequently has to determine if images and videos are real or fake. This is much more difficult to notice when AI is being used to feed you recommendations instead of generating the content itself. I would argue this can be even more impactful because of how difficult it is to notice.
To understand this, we're going to look at Spotify's music recommendation algorithm. We'll walk through it from the problem statement (what Spotify is trying to accomplish) through to the algorithms they use to accomplish that goal and all the way to the impact their methodology has on their users and the industry.
Spotify has made much more music available to many more people. The purpose of sharing this is to walk through the considerations that go into making a machine learning system, many of which go beyond choosing a model and building software.
All machine learning engineers need to understand the tradeoffs that come with approaching problems using machine learning. Machine learning is fundamentally an optimization problem, and optimizing for specific metrics always has trade-offs.
In this case study, we're going to:
Start from Spotify's problem. What are they trying to solve?
Identify how Spotify is solving that problem.
Understand the side effects their approach has.
Realize the impact those side effects have on users and the music industry as a whole.
My goal is to help you not only understand Spotify's systems, but also have a better understanding of why case studies like this are important to understanding impact.
The Problem to Solve
Like all companies, Spotify is trying to be profitable. As a music streaming service, they need to increase subscriptions. They do this by optimizing the user experience for long-term listener satisfaction, creating a personalized experience the user enjoys so they'll continue to be a subscriber.
Spotify needs to connect users with music they already enjoy and facilitate them finding new music they also enjoy. To do this, Spotify needs to create a recommendation system that feeds users the music they want. This guide will focus on how that recommendation system works and what it means for users.
This guide won't focus on other, more complex problems Spotify also has to solve, such as:
Spotify's relationship with musical artists: Spotify needs to create a reason for musical artists to include their songs on the platform so users have the songs they want, but they need to do so without compromising the user experience.
How recommendations work in different mediums: Spotify has to recommend music on the home page and as a continuity to the user's current listening. There are considerations for how each differs, but that's out of scope for this article.
Other problems such as explicit content filtering, spam identification, anything having to do with ads (recommendations, filtering, etc.), and more.
I’ll also be including technical details of Spotify’s primary recommendation algorithm, but I don’t have the space, time, or knowledge (not all information is made publicly available!) to include technical details about everything.
Let's get into it.
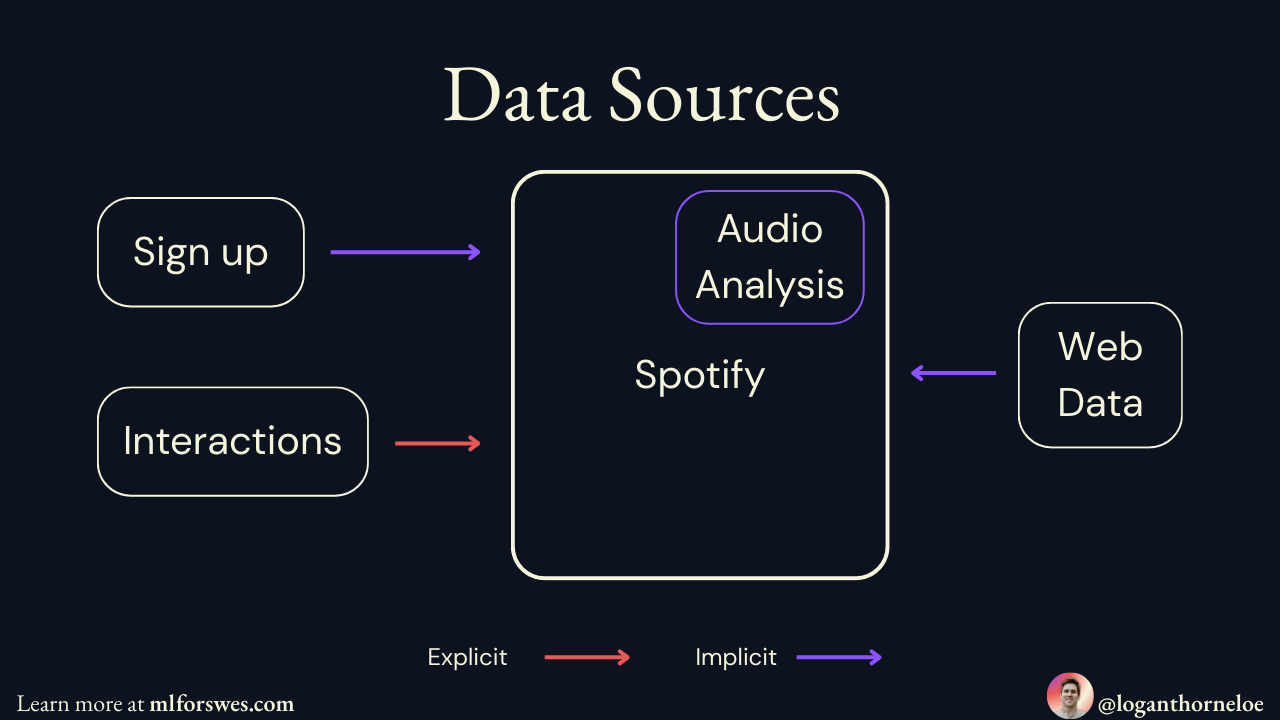
The Data
All machine learning problems start with the data. Spotify uses four categories:
All of these data points are events that are used to understand and improve the listener's experience via machine learning. Spotify processes an estimated half a trillion events daily. They need a system that can keep up with this volume.
The System
Spotify's main goal is to increase user retention by making excellent recommendations at scale. This goal comes with a number of problems that Spotify needs to solve, and we'll walk through the systems Spotify is using to solve them problem-by-problem.
This system started simply and evolved over time as Spotify's user base evolved and a more complex system was required to meet user needs. The following will give you a great understanding of how Spotify's system works based on publicly available sources and provide enough information to better understand the impact those systems have had on the music industry.
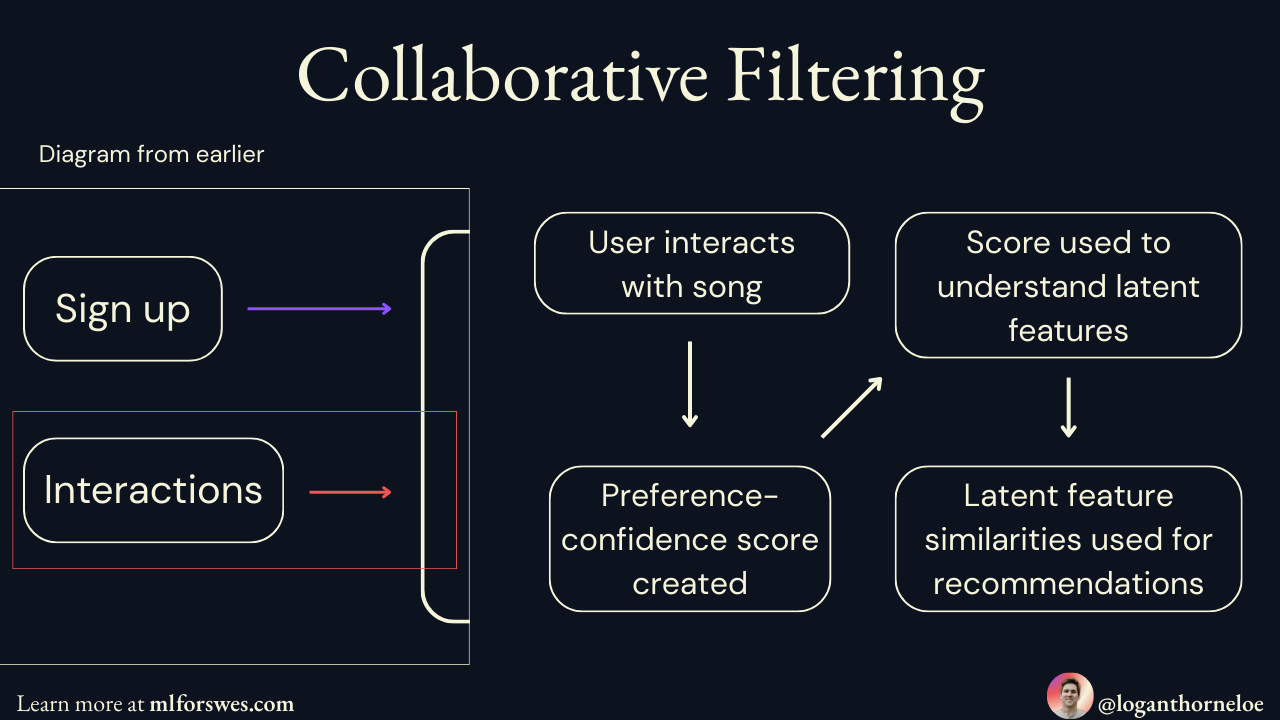
Collaborative Filtering: The Foundation Behind Recommendations
If you pay attention to one section of this article, make it this one. This is the section that part 2 of this article will focus on.
To increase user retention, the first problem Spotify needed to solve was how to recommend songs to users to keep them listening. This means using data about what a user has already listened to in order to accurately recommend their next song.
The solution Spotify used for this is called Collaborative Filtering with Implicit Feedback. Using implicit feedback is more practical for both Spotify and the listener because it doesn't require any explicit work on the listener's part (like rating songs). Instead, it uses data the user provides just by using the platform to train a machine learning model.

The Original Problem: A Massive, Mostly Empty Matrix
Put simply, imagine a giant table where every row is a user and every column is a song. Each cell contains how many times that user listened to that song (using a preference-confidence framework where listening once = low confidence, repeated listening = high confidence).
This matrix is massive. One row for each user and one column for each song means a matrix with billions (or more!) entries. The problem with this matrix is that it's sparse, or mostly empty. Since most users and songs won’t have any interaction data, the majority of the matrix won’t have any meaningful values.

Using the sparse matrix for predictions has three primary holdups:
Any computations done on this matrix would be computationally expensive. With billions of entries, calculations get expensive and slow very quickly.
Predictions are difficult. We want to find music and recommend music a user hasn’t listened to.The sparse nature of this matrix means it doesn’t help at all with this.
Adding new songs and users is impossible. New columns and rows will contain all zeroes meaning we have zero meaningful information to use for predictions.
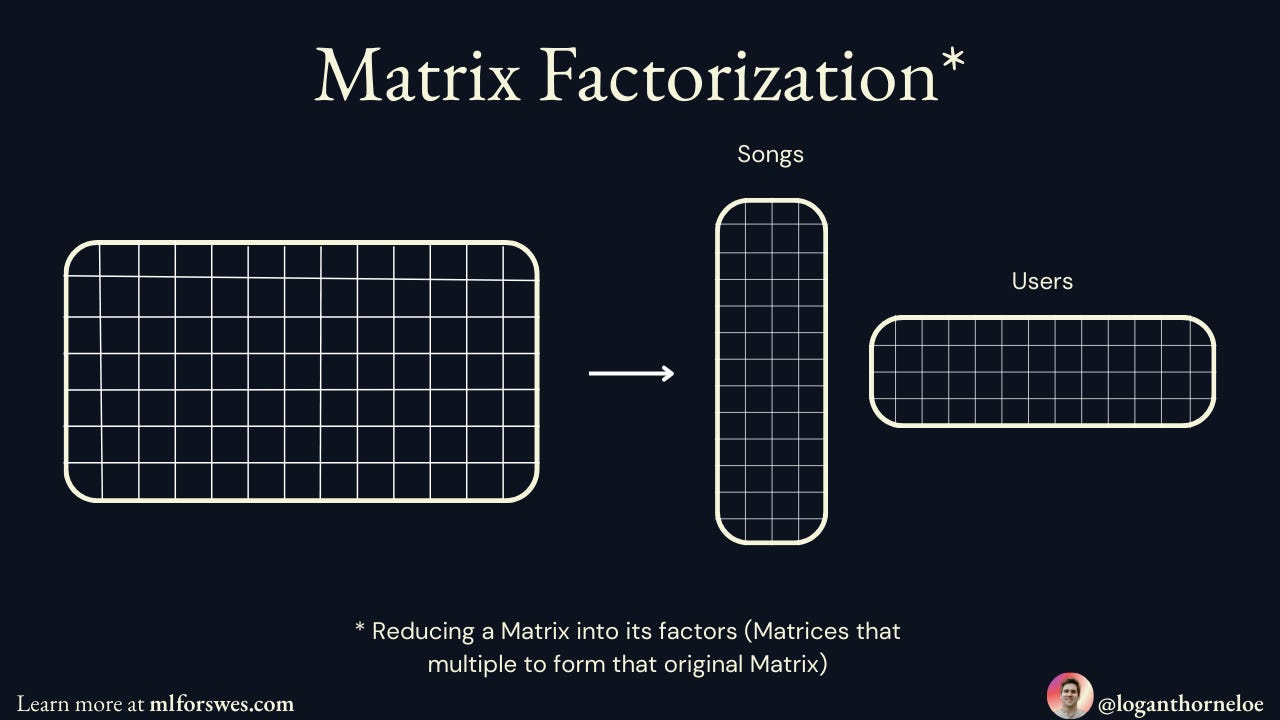
The Solution: Matrix Factorization
Matrix factorization solves this by breaking our giant sparse matrix into two much smaller, dense matrices (meaning they're filled with actual numbers, not zeroes):
A User Matrix: Each user gets a row of hidden features (like "how much does this user like rock music?" or "does this user prefer upbeat songs?")
A Song Matrix: Each song gets a column of the same hidden features (like "how rock-influenced is this song?" or "how upbeat is this song?")
When you multiply these two smaller matrices together, you get back a complete version of the original matrix—but now every cell has a predicted value, even for user-song combinations that never happened.
The exact features Spotify uses in these matrices is unknown, but the beauty of this approach is that Spotify can add and remove features as necessary since the algorithm learns their relevancy for itself.
Why These Smaller Matrices Are So Much Better
The magic is in those hidden features. The algorithm automatically learns meaningful patterns like:
User 1 has high values for "rock" and "energetic" features
Song A also has high values for "rock" and "energetic" features
Therefore, User 1 will probably like Song A (even if they've never heard it)
This is why matrix factorization works for recommendations: it discovers hidden connections between users and songs that aren't obvious from the raw listening data.
Fun fact: Factorized matrices separated into songs and users with different features for each column make it easier to add items (songs or users) to the matrices with meaningful values. Instead of randomly initializing values because implicit information isn’t known, explicit information can be used to estimate starting feature values.
I haven’t found any sources explicitly stating Spotify is doing this or how they’re doing this (they seem to solve the cold start problem differently—see ‘The Cold Start’ section below), but this is a benefit of the dense matrices worth mentioning.
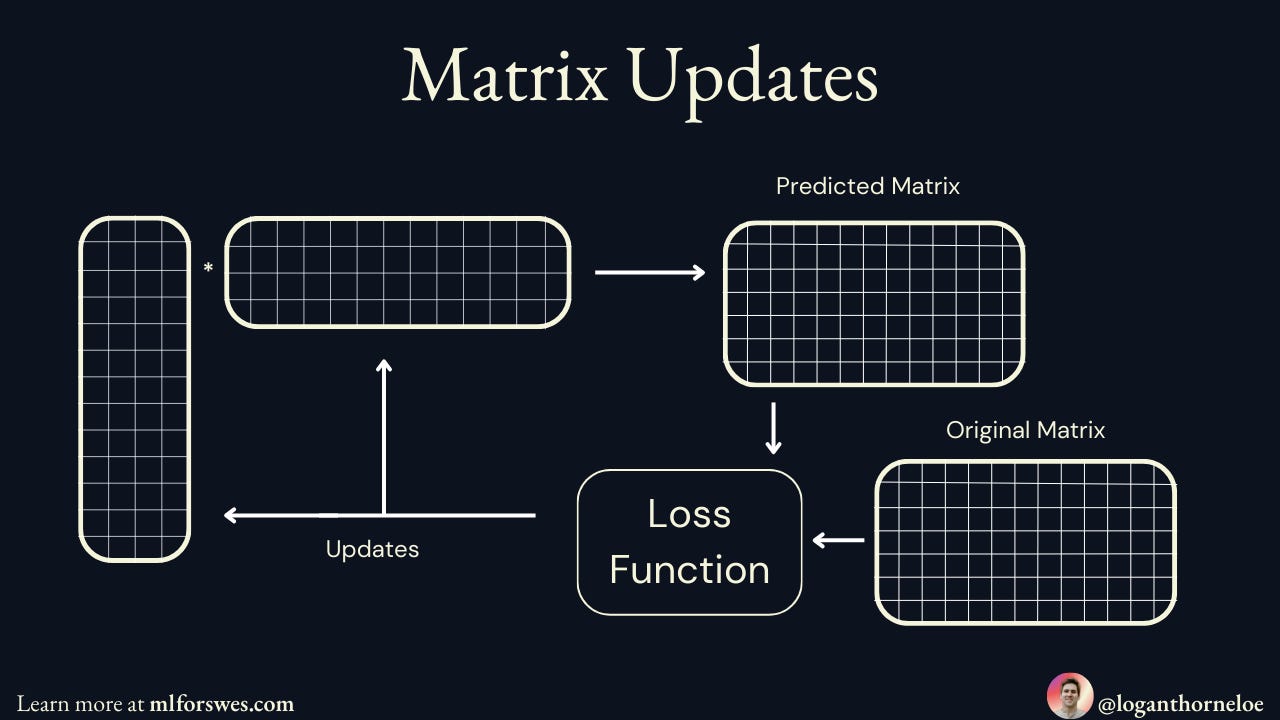
How The Algorithm Learns: Gradient Descent
The system learns these hidden features through gradient descent:
Start with random numbers in both the User Matrix and Song Matrix
Make a prediction by multiplying a user's features with a song's features
Calculate the error between the prediction and the actual listening data
Update both matrices by nudging the numbers in the direction that reduces the error
Repeat millions of times until the predictions become accurate
This process automatically discovers what those hidden features should represent to best explain the listening patterns in the data.
Making Predictions: How Recommendations Actually Work
Once the matrices are trained, generating recommendations for a user follows a straightforward process:
Calculate prediction scores: Take the user's feature vector and multiply it with every song's feature vector to get a prediction score for each song
Sort by highest scores: Rank all songs by their prediction scores for that user (highest scores = most likely to be enjoyed)
Apply filters: Remove songs the user has already heard, songs not available in their region, explicit content if filtered, etc.
Recommend the top results: Serve the highest-scoring remaining songs
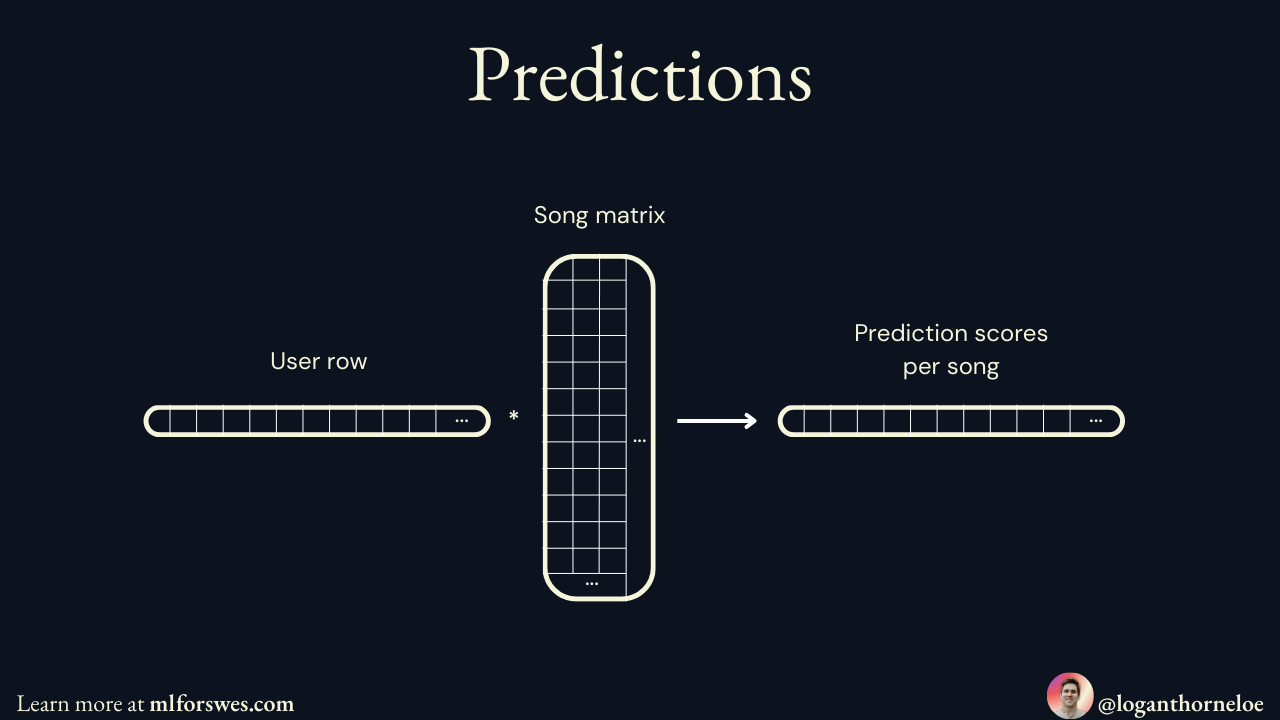
So if User 123 gets prediction scores like Song A: 0.94, Song B: 0.87, Song C: 0.82, Song D: 0.31, and they've already heard Song A, then Spotify would recommend Song B first, then Song C, and so on.
What Spotify Actually Does (The Reality)
In practice, Spotify doesn't calculate predictions for every song for every user in real-time—that would require billions of calculations per second. Instead, they likely:
Pre-calculate predictions for popular songs and store them
Use other algorithms to narrow down candidates first (maybe focusing on recently released songs or songs similar to what you've been listening to lately)
Calculate predictions on-demand for only a smaller subset of songs
But the core concept remains the same: matrix multiplication gives you prediction scores, you sort by those scores, filter out what doesn't make sense, and recommend what's left. The beauty is that this simple mathematical approach can work at Spotify's massive scale once you get clever about which predictions to calculate when.
The Cold Start
Collaborative filtering works really well for recommendation systems, but like any machine learning model, it struggles when there isn't any data to train on. This is called The Cold Start Problem. How do we make recommendations when the user hasn't interacted with the platform yet?
A popular solution to the cold start is recommending the content that is most popular or preferred by everyone. This works well in visual recommendation feeds where many of the most popular items with a bit of mix in categories can be shown on a screen at once. But this doesn't work with a music recommendation system where one song is recommended at a time. Just recommending the most popular music is sure to turn away listeners who aren't at all interested in hip hop.
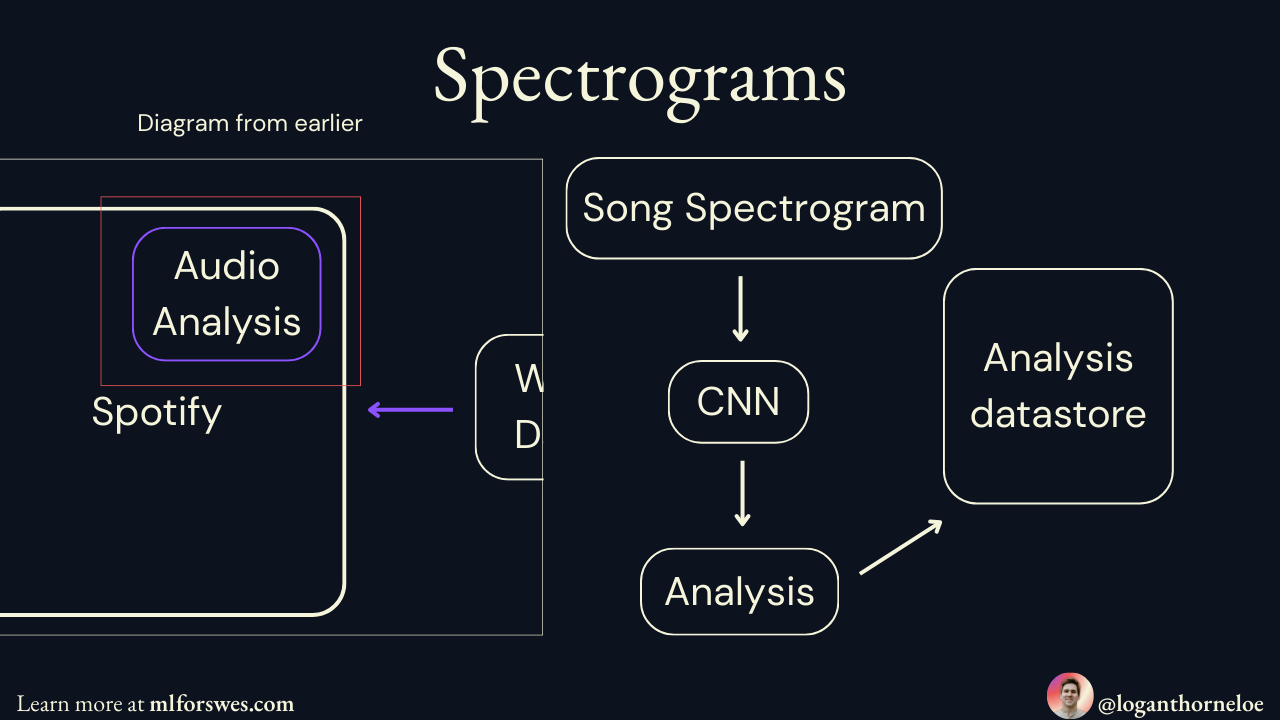
Spotify takes a different approach to this problem by leveraging popular streams with some variance on the home page menu and then using convolutional neural networks (CNNs) to analyze spectrograms (visual representations of sound) to recommend songs where the audio is similar to a song the user is already listening to.
A new user will be shown recommendations on their home page or by searching. Once they select a song, it will play and Spotify will queue recommendations after it based on how that song sounds. Once the user has listened to more songs, Spotify will create a user profile to start recommending items via collaborative filtering.
Going Past Sound
The next question Spotify engineers had to answer was how to suggest music by more than just sound. Collaborative filtering and analyzing spectrograms via CNNs lean heavily into analyzing the music preference of a user via sound. This doesn't work when the user wants music for a specific occasion, and this goes beyond what the music sounds like.
The solution was most surprising to me because it wasn't something I thought would be effective until I read more about it. Spotify uses "cultural vectorization."
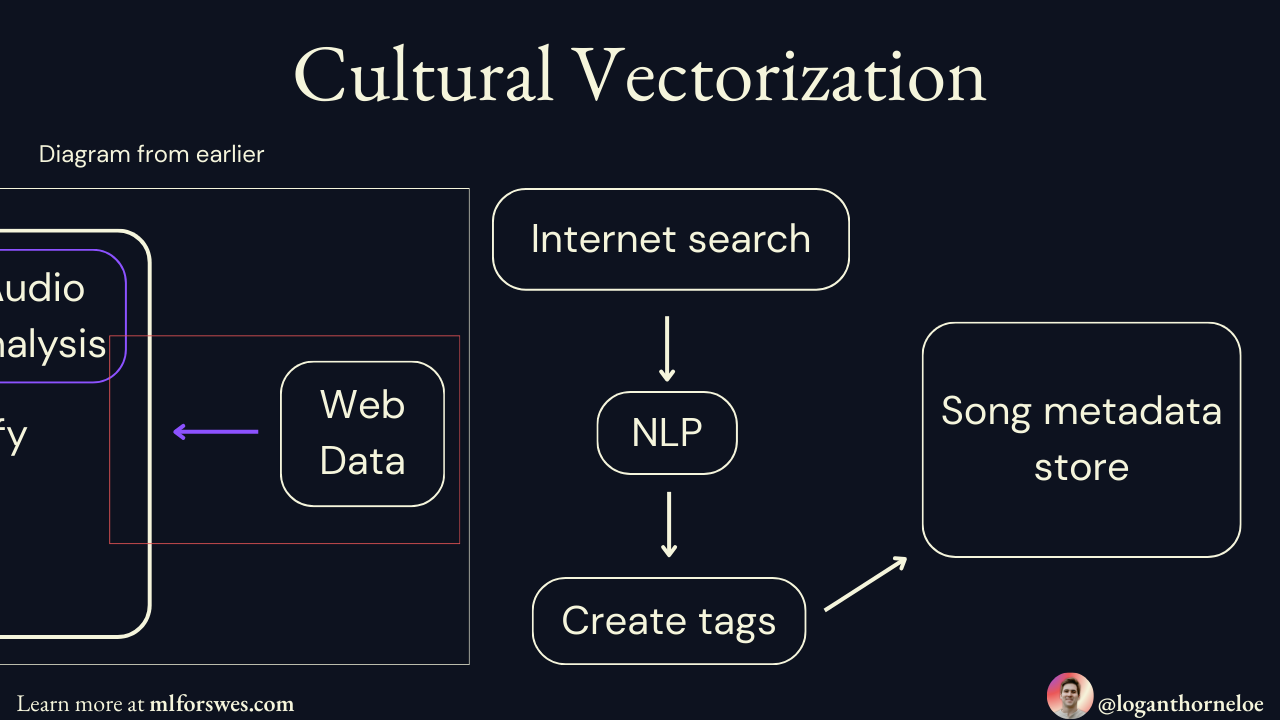
Spotify's systems will use natural language processing (NLP) to search the internet and find text relating to a song. This includes blog posts, song descriptions, and song lyrics. This processing checks the language others are using to describe songs, and Spotify's system will tag tracks based on that. These descriptors are then used for context-based recommendations.
Filling in the Gaps
Spotify uses the above methods to create a hybrid recommendation system that works for users in multiple scenarios. There are also further methods to boost music discovery via reinforcement learning (RL) and ensure less popular music is recommended to users. This is important for lesser-known artists to benefit from posting their music on Spotify's platform.
Spotify further supplements the above algorithms by having editors (human experts) curate playlists using their understanding of cultural trends. This is especially important when targeting playlists toward local markets, as it requires an understanding of cultural trends within the area to ensure the best listening experience.
I'm certain there are other problems Spotify works to solve and other algorithms used to solve them, but they're outside the scope of this article. Many likely aren't made available to the public, and all of Spotify's solutions are adapting over time.
Music is a dynamic space. Trends are changing constantly. Taste in music develops over time. Thus, all the solutions Spotify creates have to be constantly evolving with the problem they solve. Some examples of the evolution Spotify sees are:
A user's musical taste changing. All the recommendation algorithms need to be constantly trained and updated to ensure an up-to-date user profile within the recommendation system.
Overall song and musical tastes changing. Algorithms must be updated to account for changing trends in music. Human editors need to be aware of cultural shifts when curating playlists.
Technology evolves. Spotify can integrate more advanced technology to improve their algorithms and make them more efficient. This also might come in the form of new machine learning technology, which I'm sure Spotify is integrating into their platform.
The platform develops. The introduction of audiobooks required Spotify to develop an entirely new machine learning system that can leverage user music and podcast preferences to make audiobook recommendations. Audiobook data is much more sparse than musical data, requiring Spotify to leverage other data for recommendations.
All of these require constant training of models and development of new solutions.
Impact
This is where the best machine learning engineers are separated from the rest. Technical knowledge is a requirement for the role, but understanding the interplay between machine learning and the problem space in which it's creating solutions is heavily understated.
Be familiar with Goodhart's Law: "When a measure becomes a target, it ceases to be a good measure". When a metric is identified as a key metric for success, systems will start optimizing specifically for that metric, which results in behaviors that optimize for that metric but undermine the actual, broader objective.
Machine learning algorithms are trained by optimizing them for a certain measure. Successful training means an algorithm was successfully optimized for that specific metric. It doesn't necessarily mean the model achieves the objective we're hoping for. This creates a system where the tested metric can be optimized to game the system and this almost always leads to adverse outcomes.
Here's an example: Machine learning algorithms power search and are optimized for specific metrics. Those creating websites can game SEO by ensuring their website fits into what that metric decides is best to serve to a user. This creates a cat-and-mouse game where web page creators game SEO, then it changes, then they game it again. When SEO is gamed, it's a poor experience for the user.
A similar thing has happened with music recommendations. Over one-third of people get their music via a streaming service in 2025. Record labels and artists make money when people listen to their music, so knowing this, record labels will optimize music to work well with these algorithms to drive listening and increase profits.
This has had a very real impact on the song creation process. Instead of artists leading their creative process with what they want to create, they have to heavily factor in how a song will be recommended while they're creating music.

This can be noticed in modern-day songs. The first 30 seconds of a song are weighed very heavily within music recommendation systems. If a user skips a song within the first 30 seconds, the recommendation algorithm won't recommend it as much. Songs are created so the beginning of the song is engaging, meaning getting to a hook faster and having fewer drawn-out introductions.
Another way artists get around negative weighting when songs are skipped is by making songs shorter. Shorter songs are also favored by Spotify's pay-per-stream model. Since Spotify pays artists per stream instead of duration of streams, shorter songs mean listeners can stream an artist's songs more times in a shorter amount of time.
Pay-per-stream has had the biggest impact on small artists. This favors large artists considerably because they are often prominently placed in curated playlists. The algorithm has an easier time recommending those artists because they already have a large catalog of similar music that is frequently listened to. Thus, smaller artists have a hard time reaching the streaming volume required for any significant income.
When people figure out what works or what essentially games the algorithm to make it recommend a certain type of content, they'll continue to produce that type of content. This is a huge reason why we're seeing greater homogeneity in the music that's released today as opposed to the music that was released two decades ago.
Don't hate the player, hate the game
Spotify has made music far more accessible for the consumer by solving a very complex problem at scale using machine learning. The outcome is an algorithmically-driven feed that can be gamed as soon as artists understand how to do so.
While a major problem is solved, others are introduced. Spotify has continued iterating on their solution to mitigate the unintended problems that arise due to machine learning systems optimizing for a specific measure.
Streaming services have fundamentally changed the music industry and will continue to do so as algorithms evolve and change over time to make music even more accessible to the consumer.
As a machine learning engineer, studying Spotify should show you that machine learning algorithms solve complex problems, and solving those problems leads to those systems having massive impact. Any side effects of those solutions can also be largely impactful.
So when you're building machine learning algorithms, make sure you:
Understand your problem space and the right metric to target.
Study the side effects of optimizing for that metric and pay attention to how your algorithm can be gamed.
Continue iteration on the algorithm to more optimally solve the problem.
If you keep these things in mind, you can solve very complex problems elegantly.
Stay tuned for part 2, where we’ll implement our own simple collaborative filtering solution.
Thanks for reading!
Always be (machine) learning,
Logan
Hearing about music catering to an algorithm reminded me of a project I've heard about called "The People's Choice Music". The project involved two songs, each of which was made based on the results of a survey. One was based on what the survey said people liked, while the other was based on what the survey said people hated.
The "liked" song wound up being considered formulaic and dull, while the "hated" one has been described with phrases like "so bad it's good", "hilarious in its atrociousness", and "a real crackup." Oddly enough, both songs mention Wittgenstein, because "intellectual stimulation" factored into the results of both surveys.
Incidentally, two of the people behind this project have also done similar surveys for art, and created paintings based on the survey results for different countries.
I think Spotify is doing a great work in AI recommendations when the next song plays. I haven't tried creating music from Suno and Udio, though.